可能更洛谷的阅读体验
后缀数组是信息学竞赛中解决字符串匹配的一大利器,其思想和实现非常简单。虽然倍增加排序的思想很简单,但是它的拓展h t ht h t
以下应用魏老师的一句话:
几乎所有字符串算法都存在一个共性:基于所求信息的特殊性质与已经求出的信息,使用增量法与势能分析求得所有信息。这体现了动态规划思想。—— Alex_Wei
希望读者也能好好利用这句话来理解字符串算法。
本文章包含后缀数组入门,以及应用,以及技巧及其好题选讲大礼包!
但是作为本蒟蒻第一个写的算法全家桶,为了考虑到读者感受,写了一大堆没用的废话导致文章及其的长 ( •́ὤ•̀),本文章共 2.1 万字,感谢管理员付出时间来进行审核。
一些基本约定:
本文章默认字符串下表从1 1 1 我们用打字机字体表示字符串的内容,如:s = wjyppm1403 s=\texttt{wjyppm1403} s = wjyppm1403 拼接:s + t s+t s + t t t t s s s 字符集:即构成字符串中字符的集合。 空串:不含任何字符的字符串称为空串。 子串:在s s s s s s s s s s s s s [ l , r ] s[l,r] s [ l , r ] l → r l \to r l → r 匹配:称t t t s s s t t t s s s 字符串长度:我们用∣ s ∣ |s| ∣ s ∣ s s s 前后缀:
前缀:在s s s s s s p r e pre p r e 后缀:在s s s s s s s u f suf s u f 最长公共前缀:LCP ( s , t ) \operatorname{LCP}(s,t) L C P ( s , t ) s , t s,t s , t u u u u u u s , t s,t s , t LCS ( s , t ) \operatorname{LCS}(s,t) L C S ( s , t ) ∣ LCP ( s , t ) ∣ |\operatorname{LCP}(s,t)| ∣ L C P ( s , t ) ∣ 字典序:定义空字符小于任何字符。称s s s 字典序 小于t t t LCP ( s , t ) \operatorname{LCP}(s,t) L C P ( s , t ) s s s t t t i i i i i i 我们先从概念讲起。
一个字符串的后缀是指从某个位置开始到结尾的一个子串,即s u f i = s [ i → l e n ] suf_{i}=s[i \to len] s u f i = s [ i → l e n ] s = "vamamadn" s=\texttt{"vamamadn"} s = "vamamadn" 8 8 8 s u f 0 = "vamamadn" , s u f 1 = "amamadn" , s u f 2 = "mamadn" suf_{0}=\texttt{"vamamadn"},suf_{1}=\texttt{"amamadn"},suf_{2}=\texttt{"mamadn"} s u f 0 = "vamamadn" , s u f 1 = "amamadn" , s u f 2 = "mamadn"
而后缀树,就是把字符串所有后缀子串通过字典树的方法建立的一颗树。如下图:
若要在字符串上找一个子串是否出现,如"mam" \texttt{"mam"} "mam"
但是,问题在于,你全部显式的建出来那你空间不就炸掉了吗。我们思考这样的朴素后缀树的问题在哪里,这种方法的本质就是把一个长度为n n n n n n O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 )
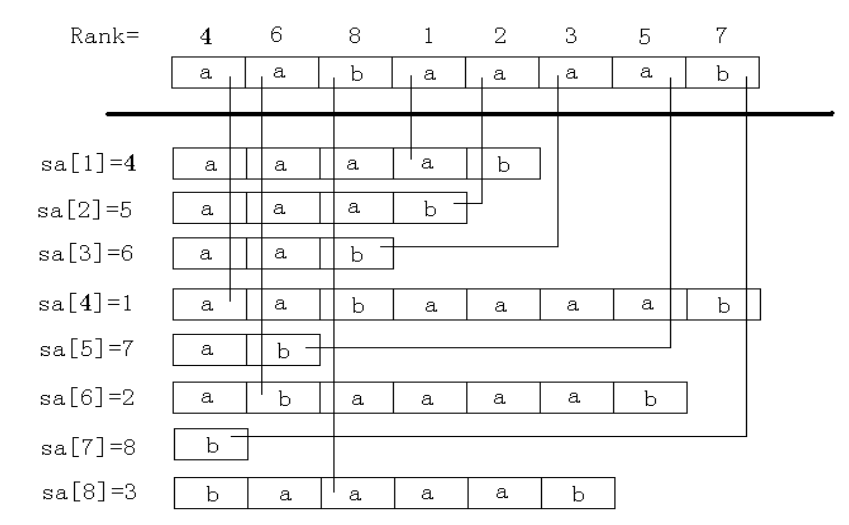
由于不方便直接对后缀树进行构造,我们利用后缀数组这种简单的方法来替代它,我们定义:s a i sa_{i} s a i i i i
那么将上面后缀树的例子,我们用后缀数组来表示一下:
后缀s u f i suf_i s u f i 下表i i i 字典序 后缀数组s a j sa_j s a j 下表j j j "vamamadn" \texttt{"vamamadn"} "vamamadn" 1 "adn" \texttt{"adn"} "adn" 6 1 "amamadn" \texttt{"amamadn"} "amamadn" 2 "amadn" \texttt{"amadn"} "amadn" 4 2 "mamadn" \texttt{"mamadn"} "mamadn" 3 "amamadn" \texttt{"amamadn"} "amamadn" 2 3 "amadn" \texttt{"amadn"} "amadn" 4 "dn" \texttt{"dn"} "dn" 7 4 "madn" \texttt{"madn"} "madn" 5 "madn" \texttt{"madn"} "madn" 5 5 "adn" \texttt{"adn"} "adn" 6 "mamadn" \texttt{"mamadn"} "mamadn" 3 6 "dn" \texttt{"dn"} "dn" 7 "n" \texttt{"n"} "n" 8 7 "n" \texttt{"n"} "n" 8 "vamamadn" \texttt{"vamamadn"} "vamamadn" 1 8
很明显,后缀数组的下表对应的就是后缀子串的字典顺序,记录的子串的有序排列。例如s a 1 = 5 sa_{1}=5 s a 1 = 5 1 1 1 5 5 5
上面是一个例子,下面是 OI-Wiki 的例子:
我们定义另外一个数组r k rk r k s u f i suf_{i} s u f i r k rk r k s a sa s a
s a sa s a r k rk r k 那么有s a ( r k [ i ] ) = i , r k ( s a [ i ] ) = i sa(rk[i])=i,rk(sa[i])=i s a ( r k [ i ] ) = i , r k ( s a [ i ] ) = i
那么现在问题在于如何给这些后缀通过排序求出排名。有一个显而易见的想法是从最后一位开始枚举后缀,然后每次存下当前枚举到的字符串,最后排序并输出就 OK 辣!
但是这样显然复杂度起步就是O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 log n ) O(n^2 \log n) O ( n 2 log n )
但是我们考虑,我们每一次都是一位一位比较的,我们能不能多位进行比较呢。这个时候我们就要用到倍增 的思想:
首先对字符串s s s 1 1 1 s a i sa_{i} s a i r k i rk_{i} r k i
第二次,我们根据倍增向后移2 0 = 1 2^0=1 2 0 = 1 r a n k rank r a n k
第三次,移2 1 = 2 2^1=2 2 1 = 2 r a n k rank r a n k
第四次:
唉?我们好像倍增完了,这样的话我们就求得了所有的r a n k rank r a n k s a ( r k [ i ] ) = i sa(rk[i])=i s a ( r k [ i ] ) = i s a sa s a O ( n log n ) O(n \log n) O ( n log n ) O ( log n ) O(\log n) O ( log n ) O ( n log 2 n ) O(n \log^2 n) O ( n log 2 n )
再看一遍整体的过程:
但是这样显然过不去我们可爱的 P3809,因为它要求O ( n log n ) O(n\log n) O ( n log n ) O ( n log n ) O(n \log n) O ( n log n ) O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void getsa () for (int i=1 ;i<=n;i++){ x[i]=s[i]; c[x[i]]++; } for (int i=1 ;i<=m;i++){ c[i]+=c[i-1 ]; } for (int i=n;i>=1 ;i--){ sa[c[x[i]]--]=i; } for (int len=1 ;len<=n;len<<=1 ){ int num=0 ; for (int i=n-len+1 ;i<=n;i++){ y[++num]=i; } for (int i=1 ;i<=n;i++){ if (sa[i]>len) y[++num]=sa[i]-len; } for (int i=1 ;i<=m;i++) c[i]=0 ; for (int i=1 ;i<=n;i++) c[x[i]]++; for (int i=1 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=n;i>=1 ;i--){ sa[c[x[y[i]]]--]=y[i]; y[i]=0 ; } swap (x,y); num=1 ; x[sa[1 ]]=1 ; for (int i=2 ;i<=n;i++){ if (y[sa[i]]==y[sa[i-1 ]]&&y[sa[i]+len]==y[sa[i-1 ]+len]) x[sa[i]]=num; else x[sa[i]]=++num; } if (num==n) break ; m=num; } }
关于成熟的模板我们之后再说。对于上面的内容其实都比较还算简单,但是 SA 真正的神就在于 Height 数组,我们这里简称为h t ht h t
回顾 LCP 的定义:
最长公共前缀:LCP ( s , t ) \operatorname{LCP}(s,t) L C P ( s , t ) s , t s,t s , t u u u u u u s , t s,t s , t
而 Height 数组的定义就是:h t [ i ] = LCP ( s a [ i ] , s a [ i − 1 ] ) ht[i]=\operatorname{LCP}(sa[i],sa[i-1]) h t [ i ] = L C P ( s a [ i ] , s a [ i − 1 ] ) i i i h t [ 1 ] = 0 ht[1]=0 h t [ 1 ] = 0
绝大多数 SA 的应用都需要h t ht h t s a , r k sa,rk s a , r k s a sa s a h t ht h t
那么怎么求?有一个朴素的想法就是哈希加二分,这个想必读者在做哈希题经常会见到这种操作。不然为什么我们标题叫哈希乱搞到入门 ,我们有一个结论:
若r k i < r k j < r k k rk_{i}<rk_{j}<rk_{k} r k i < r k j < r k k ∣ LCP ( i , j ) ∣ |\operatorname{LCP}(i,j)| ∣ L C P ( i , j ) ∣ ∣ LCP ( j , k ) ∣ |\operatorname{LCP}(j,k)| ∣ L C P ( j , k ) ∣ ∣ LCP ( i , k ) ∣ |\operatorname{LCP}(i,k)| ∣ L C P ( i , k ) ∣
证明?设t = ∣ LCP ( i , k ) ∣ t=|\operatorname{LCP}(i,k)| t = ∣ L C P ( i , k ) ∣ s u f j suf_{j} s u f j s u f i , s u f k suf_{i},suf_{k} s u f i , s u f k s u f j suf_{j} s u f j t t t s u f i , s u f k suf_{i},suf_{k} s u f i , s u f k
若我们希望不要O ( n log n ) O(n \log n) O ( n log n ) h t ht h t
假设h t i ht_i h t i ∣ LCP ( s a i , s a i − 1 ) ∣ = h t i |\operatorname{LCP}(sa_{i},sa_{i-1})|=ht_{i} ∣ L C P ( s a i , s a i − 1 ) ∣ = h t i s u f ( s a i − 1 + 1 ) , s u f ( s a i + 1 ) suf(sa_{i-1}+1),suf(sa_{i}+1) s u f ( s a i − 1 + 1 ) , s u f ( s a i + 1 ) h t i > 0 ht_{i}>0 h t i > 0 ∣ LCP ( s a i + 1 , s a i − 1 + 1 ) ∣ = h t i − 1 |\operatorname{LCP}(sa_{i}+1,sa_{i-1}+1)|=ht_{i}-1 ∣ L C P ( s a i + 1 , s a i − 1 + 1 ) ∣ = h t i − 1 r k ( s a i − 1 ) < r k ( s a i ) rk(sa_{i-1})<rk(sa_{i}) r k ( s a i − 1 ) < r k ( s a i ) r k ( s a i − 1 + 1 ) < r k ( s a i + 1 ) rk(sa_{i-1}+1)<rk(sa_{i}+1) r k ( s a i − 1 + 1 ) < r k ( s a i + 1 )
令p = s a i + 1 , q = s a i − 1 + 1 p=sa_{i}+1,q=sa_{i-1}+1 p = s a i + 1 , q = s a i − 1 + 1 r k p rk_{p} r k p h t ht h t
∣ LCP ( p , q ) ∣ = h t i − 1 |\operatorname{LCP}(p,q)|=ht_{i}-1 ∣ L C P ( p , q ) ∣ = h t i − 1 r k ( q ) < r k ( p ) rk(q)<rk(p) r k ( q ) < r k ( p ) 我们考虑,排名为r k p − 1 rk_{p}-1 r k p − 1 s u f r suf_r s u f r r k q rk_q r k q q = r q=r q = r r k q , r k p rk_q,rk_p r k q , r k p r k r rk_r r k r r k p rk_p r k p r k p − 1 rk_{p}-1 r k p − 1 r k q rk_q r k q r k p rk_p r k p h t ( r k p ) ≥ h t i − 1 ht(rk_{p})\ge ht_{i}-1 h t ( r k p ) ≥ h t i − 1 r k p rk_{p} r k p h t ( r k ( s a i + 1 ) ) ≥ h t ( r k ( s a i ) ) − 1 ht(rk(sa_{i}+1))\ge ht(rk(sa_{i}))-1 h t ( r k ( s a i + 1 ) ) ≥ h t ( r k ( s a i ) ) − 1 u = s a i + 1 u=sa_{i}+1 u = s a i + 1 h t ht h t
h t ( r k u ) ≥ h t ( r k u − 1 ) − 1 ht(rk_{u})\ge ht(rk_{u-1})-1 h t ( r k u ) ≥ h t ( r k u − 1 ) − 1
我们这里引用 Alex_Wei 的图:
通过这个性质,我们可以通过类似于双指针的性质来暴力求解h t ht h t
1 2 3 4 5 6 7 8 for (int i=1 ;i<=len;i++) rk[sa[i]]=i;for (int i=1 ,k=0 ;i<=len;i++){ if (rk[i]==1 ) continue ; if (k) k--; int j=sa[rk[i]-1 ]; while (i+k<=len&&j+k<=len&&s[i+k]==s[j+k]) k++; ht[rk[i]]=ST[0 ][rk[i]]=k; }
下面是一个完整的模板,但是里面有一些函数还没有讲解,在应用中我们会逐个讲解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 namespace SA{ int len,sa[MN],x[MN],y[MN],rk[MN],c[MN],ht[MN],ST[30 ][MN]; template <typename vct> void getsa (vct &s) { int m=400000 ; len=s.size (); s.insert (s.begin (),' ' ); for (int i=1 ;i<=len;i++){ x[i]=s[i]; ++c[x[i]]; } for (int i=2 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=len;i>=1 ;i--) sa[c[x[i]]--]=i; for (int k=1 ;k<=len;k<<=1 ){ int num=0 ; for (int i=len-k+1 ;i<=len;i++) y[++num]=i; for (int i=1 ;i<=len;i++){ if (sa[i]>k) y[++num]=sa[i]-k; } for (int i=1 ;i<=m;i++) c[i]=0 ; for (int i=1 ;i<=len;i++) c[x[i]]++; for (int i=2 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=len;i>=1 ;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0 ; swap (x,y); num=1 ,x[sa[1 ]]=1 ; for (int i=2 ;i<=len;i++){ if (y[sa[i]]==y[sa[i-1 ]]&&y[sa[i]+k]==y[sa[i-1 ]+k]) x[sa[i]]=num; else x[sa[i]]=++num; } if (num==len) break ; m=num; } for (int i=1 ;i<=len;i++) rk[sa[i]]=i; for (int i=1 ,k=0 ;i<=len;i++){ if (rk[i]==1 ) continue ; if (k) k--; int j=sa[rk[i]-1 ]; while (i+k<=len&&j+k<=len&&s[i+k]==s[j+k]) k++; ht[rk[i]]=ST[0 ][rk[i]]=k; } } void initst () for (int i=1 ;i<30 ;i++){ for (int j=1 ;j+(1 <<i)-1 <=len;j++){ ST[i][j]=min (ST[i-1 ][j],ST[i-1 ][j+(1 <<(i-1 ))]); } } } int querylcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (ST[d][l],ST[d][r-(1 <<d)+1 ]); } }
后缀数组有着许许多多的应用,但是由于对应的例题过于杂且用到的芝士较多,我们的顺序是先讲解技巧,先认识,让后我们在最后一部分的习题环节进行练习。有一些应用是对应少见的例题,所以这里会直接进行讲解而不会放在习题。
循环移动位置实际上就是将字符串排为一个环,让后旋转这个环,我们先要断环成链将给定字符串复制一遍放在后面,这样就变为了后缀排序问题。
我们发现,循环移动位置实际上就是将字符串排为一个环,让后旋转这个环,我们先要断环成链。把给定字符串复制一遍放在后面。让后你发现题目其实就是把这个改变后的字符串进行后缀排序,我们根据后缀排序的数组让后输出对应最后一位就可以了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <bits/stdc++.h> using namespace std;constexpr int MN=8e5 +15 ;int x[MN],n,m,y[MN],c[MN],sa[MN];string s; void getsa () for (int i=1 ;i<=n;i++){ x[i]=s[i]; c[x[i]]++; } for (int i=2 ;i<=m;i++){ c[i]+=c[i-1 ]; } for (int i=n;i>=1 ;i--){ sa[c[x[i]]--]=i; } for (int len=1 ;len<=n;len<<=1 ){ int num=0 ; for (int i=n-len+1 ;i<=n;i++){ y[++num]=i; } for (int i=1 ;i<=n;i++){ if (sa[i]>len){ y[++num]=sa[i]-len; } } for (int i=1 ;i<=m;i++){ c[i]=0 ; } for (int i=1 ;i<=n;i++){ c[x[i]]++; } for (int i=2 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=n;i>=1 ;i--){ sa[c[x[y[i]]]--]=y[i]; y[i]=0 ; } swap (x,y); num=1 ; x[sa[1 ]]=1 ; for (int i=2 ;i<=n;i++){ if (y[sa[i]]==y[sa[i-1 ]]&&y[sa[i]+len]==y[sa[i-1 ]+len]){ x[sa[i]]=num; }else x[sa[i]]=++num; } } } int main () cin>>s; n=s.length ()*2 ; m=300000 ; s=' ' +s+s; getsa (); for (int i=1 ;i<=n;i++){ if (sa[i]<=n/2 ) cout<<s[sa[i]+n/2 -1 ]; } return 0 ; }
细节我给同学讲解 Trie 习题后教练考我这个问题,还好我即会后缀数组也会哈希做法 www。
同学问我哈希怎么做,显然最长公共子串的长度满足可二分性,考虑二分最长公共子串长度L L L L L L O ( n log n ) O(n \log n) O ( n log n )
如何用 SA 做呢?现在我们要求在主串T T T S S S T T T S S S T T T T T T S S S S S S O ( ∣ S ∣ ) O(|S|) O ( ∣ S ∣ ) O ( ∣ S ∣ log ∣ T ∣ ) O(|S| \log |T|) O ( ∣ S ∣ log ∣ T ∣ ) T T T
这一部分主要考察二分的操作使用,在下面的例题中我们也会详细的进行讲解。
给你一个字符串,每次从首或尾取一个字符组成字符串,问所有能够组成的字符串中字典序最小的一个。
例题:「USACO07DEC」Best Cow Line 。
一个暴力的想法就是O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <bits/stdc++.h> using namespace std;constexpr int MN=2e6 +15 ;int x[MN],y[MN],rk[MN],sa[MN],c[MN],n,sn,m;string s,revs; void getsa () for (int i=1 ;i<=n;i++){ x[i]=s[i]; c[x[i]]++; } for (int i=1 ;i<=m;i++){ c[i]+=c[i-1 ]; } for (int i=n;i>=1 ;i--){ sa[c[x[i]]--]=i; } for (int len=1 ;len<=n;len<<=1 ){ int num=0 ; for (int i=n-len+1 ;i<=n;i++){ y[++num]=i; } for (int i=1 ;i<=n;i++){ if (sa[i]>len){ y[++num]=sa[i]-len; } } memset (c,0 ,sizeof (c)); for (int i=1 ;i<=n;i++){ c[x[i]]++; } for (int i=1 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=n;i>=1 ;i--){ sa[c[x[y[i]]]--]=y[i]; y[i]=0 ; } swap (x,y); num=1 ; x[sa[1 ]]=1 ; for (int i=2 ;i<=n;i++){ if (y[sa[i]]==y[sa[i-1 ]]&&y[sa[i]+len]==y[sa[i-1 ]+len]){ x[sa[i]]=num; }else x[sa[i]]=++num; } } for (int i=1 ;i<=n;i++){ rk[sa[i]]=i; } } int main () cin>>n; m=5e5 ; for (int i=1 ;i<=n;i++){ char awa; cin>>awa; s.push_back (awa); } for (int i=s.length ()-1 ;i>=0 ;i--){ revs.push_back (s[i]); } sn=n; s=' ' +s+(char )0 +revs; n=(n*2 +1 ); getsa (); int tot=0 ; for (int l=1 ,r=sn;l<=r;){ if (rk[l]<rk[n+1 -r]){ cout<<s[l++]; }else cout<<s[r--]; if ((++tot)%80 ==0 ) cout<<'\n' ; } return 0 ; }
对于后缀数组,在贪心和 DP 中一般不作为主角出现,多用于字符串加速匹配的问题或者利用其性质进行求解。
某些题目让你求满足条件的前若干个数,而这些数又在后缀排序中的一个区间内。这时我们可以用归并排序的性质来合并两个结点的信息,利用线段树维护和查询区间答案。
同时后缀数组会根据题目的不同结合一系列数据结构算法,如莫队,扫描线等。在习题部分我们会单独开讲。
有了h t ht h t s s s i i i j j j LCP ( i , j ) \operatorname{LCP}(i,j) L C P ( i , j )
结论如下:
若r k i < r k j rk_{i}<rk_{j} r k i < r k j ∣ LCP ( i , j ) ∣ = min p = r k i + 1 r k j h t p |\operatorname{LCP}(i,j)|=\min\limits_{p=rk_{i}+1}^{rk_{j}}ht_p ∣ L C P ( i , j ) ∣ = p = r k i + 1 min r k j h t p
感性理解以下,如果H e i g h t Height H e i g h t
严格证明可以参考[2004] 后缀数组 by. 许智磊 。那么通过这样,求两子串最长公共前缀就转化为了 RMQ 问题,这也就是对应了我们模板中的 ST 表,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void initst () for (int i=1 ;i<30 ;i++){ for (int j=1 ;j+(1 <<i)-1 <=len;j++){ ST[i][j]=min (ST[i-1 ][j],ST[i-1 ][j+(1 <<(i-1 ))]); } } } int querylcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); }
我们这里引用 Alex_wei 的图:
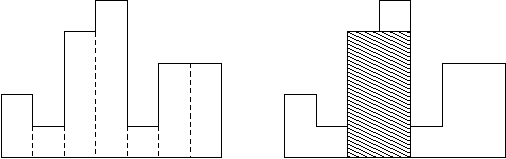
上图就是对aabaaaab \texttt{aabaaaab} aabaaaab h t ht h t h t ht h t
但是,如果我们将整张图逆着旋转90 90 9 0
我们得到了一个矩形柱状图!h t ht h t
没错,这个玩意我们还是可以和单调栈结合起来一起考的!众所周知,单调栈可以求出柱状图中面积最大的矩形。
例如我们求所有后缀两两 LCP 长度之和,考虑按排名顺序加入所有后缀并实时维护F ( i ) = ∑ p = 1 i − 1 ∣ LCP ( s a p , s a i ) ∣ F(i)=\sum\limits_{p=1}^{i-1}|\operatorname{LCP}(sa_{p},sa_{i})| F ( i ) = p = 1 ∑ i − 1 ∣ L C P ( s a p , s a i ) ∣ ∑ p = 1 i − 1 min q = p + 1 i h t q \sum\limits_{p=1}^{i-1} \min\limits_{q=p+1}^{i} ht_{q} p = 1 ∑ i − 1 q = p + 1 min i h t q h t i ht_{i} h t i 1 1 1
可以用s s s n ( n + 1 ) 2 \dfrac{n(n+1)}{2} 2 n ( n + 1 ) ∣ LCP ( i , j ) ∣ = min p = r k i + 1 r k j h t p |\operatorname{LCP}(i,j)|=\min\limits_{p=rk_{i}+1}^{rk_{j}}ht_p ∣ L C P ( i , j ) ∣ = p = r k i + 1 min r k j h t p n ( n + 1 ) 2 − ∑ i = 2 n h t i \dfrac{n(n+1)}{2}-\sum\limits_{i=2}^n ht_{i} 2 n ( n + 1 ) − i = 2 ∑ n h t i
上面的做法我们求得了s s s s s s S S S
设S S S p 1 , p 2 , … , p ∣ S ∣ p_1,p_2,\dots,p_{|S|} p 1 , p 2 , … , p ∣ S ∣
( ∑ i = 1 ∣ S ∣ n − p i + 1 ) − ( ∑ i = 1 ∣ S ∣ − 1 ∣ LCP ( p i , p i + 1 ) ∣ ) \left( \sum\limits_{i=1}^{|S|} n-p_{i}+1 \right)-\left(\sum\limits_{i=1}^{|S|-1} |\operatorname{LCP}(p_{i},p_{i+1})| \right) ⎝ ⎛ i = 1 ∑ ∣ S ∣ n − p i + 1 ⎠ ⎞ − ⎝ ⎛ i = 1 ∑ ∣ S ∣ − 1 ∣ L C P ( p i , p i + 1 ) ∣ ⎠ ⎞
其中后面能够 ST 表预处理后O ( ∣ S ∣ ) O(|S|) O ( ∣ S ∣ )
给出n n n s 1 , s 2 , … , s n s_{1},s_{2},\dots,s_{n} s 1 , s 2 , … , s n
首先我们先把这个字符串给拼接起来,格式入t = s 1 + c 1 + s 2 + c 2 + ⋯ + c n − 1 + s n t=s_{1}+c_{1}+s_{2}+c_{2}+\dots +c_{n-1}+s_{n} t = s 1 + c 1 + s 2 + c 2 + ⋯ + c n − 1 + s n c i = ’z’ + i c_{i}=\texttt{'z'}+i c i = ’z’ + i
让后我们对t t t max 1 ≤ l ≤ r ≤ ∣ t ∣ min p = l + 1 r ∣ LCP ( p , p − 1 ) ∣ \max\limits_{1\le l \le r \le |t|} \min_{p=l+1}^r |\operatorname{LCP}(p,p-1)| 1 ≤ l ≤ r ≤ ∣ t ∣ max min p = l + 1 r ∣ L C P ( p , p − 1 ) ∣ [ l , r ] [l,r] [ l , r ] s i s_i s i
容易发现l l l r r r O ( n + n log n ) O(n+n \log n) O ( n + n log n )
某些题目求解时要求你将后缀数组划分成若干个连续 LCP 长度大于等于某一值的段,我们可以考虑根据h t ht h t L L L < L <L < L h t ht h t h t ht h t L L L h t i ht_{i} h t i s a i − 1 , s a i sa_{i-1},sa_{i} s a i − 1 , s a i ≥ L \ge L ≥ L
对h t i ht_{i} h t i
如果题目中出现一些构造字符串循环构成的问题,我们可以不妨考虑枚举这个循环的长度L L L L L L L L L 看似全局的问题局部化解决 。对应到后缀数组上就是对相邻两块的块进行 LCP 和 LCS 查询,具体如何操作我们下面会讲解。
呃其实就是板子题,这个真没有什么好说的,考虑从从大到小添加每个h t i ht_{i} h t i s a i − 1 , s a i sa_{i-1},sa_{i} s a i − 1 , s a i k k k h t i ht_{i} h t i
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int n,k;string a; multiset<int > tt; namespace SA{}using namespace SA; int main () cin>>n>>k; k--; for (int i=1 ;i<=n;i++){ int c; cin>>c; a.push_back (c); } getsa (a); int ans=0 ; for (int i=1 ;i<=n;i++){ tt.insert (ht[i]); if (i>k) tt.erase (tt.find (ht[i-k])); ans=max (ans,*tt.begin ()); } cout<<ans; return 0 ; }
若r r r r ′ ( 1 ≤ r ′ < r ) r'(1\le r' < r) r ′ ( 1 ≤ r ′ < r ) ≥ L \ge L ≥ L h t i ht_{i} h t i s a i − 1 , s a i sa_{i-1},sa_{i} s a i − 1 , s a i p , q p,q p , q p , q p,q p , q L L L
我们考虑从大到小处理h t i ht_{i} h t i L L L O ( n log 2 n ) O(n \log^2 n) O ( n log 2 n ) O ( n log n ) O(n \log n) O ( n log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <bits/stdc++.h> #define ll long long using namespace std;constexpr int MN=6e5 +15 ;int n,m,x[MN],y[MN],cnt[MN],pre[MN],sa[MN],rk[MN],h[MN],pos[MN];ll mx[MN],mn[MN],ans1[MN],ans2[MN],ans[MN],a[MN],siz[MN]; string s; namespace SA{}using namespace SA; void geth () for (int i=1 ,k=0 ;i<=n;i++){ if (!rk[i]) continue ; if (k) k--; while (s[i+k]==s[sa[rk[i]-1 ]+k]) k++; h[rk[i]]=k; } } void init () memset (ans2,128 ,sizeof (ans2)); for (int i=1 ;i<=n;i++){ pre[i]=i; pos[i]=i; mx[i]=mn[i]=a[i]; ans[i]=-1e18 ; siz[i]=1 ; } } int root (int x) if (pre[x]==x) return pre[x]; else return pre[x]=root (pre[x]); } void merge (int x,int y,int len) x=root (x),y=root (y); pre[y]=x; ans1[len]+=(ll)siz[x]*siz[y]; siz[x]+=siz[y]; ans[x]=max ({ans[x],ans[y],mx[x]*mx[y],mx[x]*mn[y],mn[x]*mx[y],mn[x]*mn[y]}); mx[x]=max (mx[x],mx[y]); mn[x]=min (mn[x],mn[y]); ans2[len]=max (ans2[len],ans[x]); } bool cmp (int x,int y) return h[x]>h[y]; } int main () cin>>n; m=3e5 ; cin>>s; s=' ' +s; for (int i=1 ;i<=n;i++) cin>>a[i]; getsa (); geth (); init (); sort (pos+2 ,pos+1 +n,cmp); for (int i=2 ;i<=n;i++){ merge (sa[pos[i]],sa[pos[i]-1 ],h[pos[i]]); } for (int i=n;i>=0 ;i--) ans1[i]+=ans1[i+1 ]; for (int i=n;i>=0 ;i--) ans2[i]=max (ans2[i],ans2[i+1 ]); for (int i=0 ;i<n;i++){ cout<<ans1[i]<<" " <<(ans1[i]?ans2[i]:0 )<<'\n' ; } return 0 ; }
我们考虑,每一次修改修改的都是一段后缀,启发我们对a + b a+b a + b
那么,我们利用上面的思路,从大到小将h t i ht_{i} h t i a , b a,b a , b O ( n log n ) O(n \log n) O ( n log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <bits/stdc++.h> #define int long long using namespace std;constexpr int MN=1e6 +15 ;int n,ans,K,as[MN],bs[MN],pre[MN];string a,b,s; vector<int > pos[MN]; namespace SA{ }using namespace SA; int root (int x) if (pre[x]==x) return pre[x]; else return pre[x]=root (pre[x]); } void merge (int x,int y,int lcpl) int rx=root (x),ry=root (y); if (rx==ry) return ; int tmp=min (as[rx],bs[ry]); ans+=max (0ll ,K-lcpl)*tmp; as[rx]-=tmp; bs[ry]-=tmp; tmp=min (bs[rx],as[ry]); ans+=max (0ll ,K-lcpl)*tmp; bs[rx]-=tmp; as[ry]-=tmp; as[ry]=as[rx]+as[ry],bs[ry]=bs[rx]+bs[ry]; pre[rx]=ry; } signed main () ios::sync_with_stdio (0 ); cin.tie (0 ); cout.tie (0 ); cin>>n>>K>>a>>b; s=a+'#' +b; for (int i=1 ;i<=n;i++){ as[i]=(i+K-1 <=n); } for (int i=n+2 ;i<=2 *n+1 ;i++){ bs[i]=(i-n-1 +K-1 <=n); } for (int i=0 ;i<=2 *n+1 ;i++){ pre[i]=i; } getsa (s); initst (); for (int i=n;i>=0 ;i--){ for (auto p:pos[i]){ merge (sa[p],sa[p-1 ],i); } } put (ans); return 0 ; }
形式化题面如下:
给定一个长为n n n q q q [ l , r ] [l,r] [ l , r ]
1 ≤ n ≤ 5 × 1 0 4 , 1 ≤ q ≤ 1 0 5 1\le n \le 5\times 10^4,1\le q \le 10^5 1 ≤ n ≤ 5 × 1 0 4 , 1 ≤ q ≤ 1 0 5
没有形式化题面感觉都想不出来怎么做 www。
肯定没有那么菜啦,首先考虑二分长度,问题转化为区间内是否存在一个长为m i d mid m i d
接下来我们考虑这个最长重复子串怎么求,一个比较明显的想法就是后缀数组的 LCP 功能,原命题询问的实质就问是否存在i , j ∈ [ l , r − m i d + 1 ] , LCP ( i , j ) ≥ m i d i,j \in [l,r-mid+1],\operatorname{LCP}(i,j)\ge mid i , j ∈ [ l , r − m i d + 1 ] , L C P ( i , j ) ≥ m i d 品酒大会 的思路:从大到小将 Height 数组插入,若仅考虑≥ L \ge L ≥ L s a i − 1 , s a i sa_{i-1},sa_{i} s a i − 1 , s a i p , q p,q p , q LCP ( p , q ) ≥ L \operatorname{LCP}(p,q)\ge L L C P ( p , q ) ≥ L O ( log n ) O(\log n) O ( log n )
但是有点问题啊,如果我们直接这么做我们并没有考虑区间位置,也就是说在两个联通块启发式合并的时候我们必须要记录区间的位置。我们不妨考虑对于联通块内每一个位置,我们维护它在当前联通块内上一个元素的位置,记作p r e i pre_{i} p r e i max i ∈ s e t ( L ) , i ∈ [ l , r − L + 1 ] p r e i ≥ l \max\limits_{i\in set(L),i\in [l,r-L+1]} pre_{i}\ge l i ∈ s e t ( L ) , i ∈ [ l , r − L + 1 ] max p r e i ≥ l O ( q log 2 n O(q \log^2 n O ( q log 2 n log \log log
问题转化为如何维护p r e pre p r e L L L p r e pre p r e O ( log n ) O(\log n) O ( log n ) p r e pre p r e O ( n log 2 n ) O(n \log^2 n) O ( n log 2 n ) O ( q log 2 n + n log 2 n ) O(q\log^2 n + n \log^2 n) O ( q log 2 n + n log 2 n )
请注意二分的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #include <bits/stdc++.h> #define pir pair<int,int> using namespace std;constexpr int MN=5e4 +15 ;int n,q,pre[MN];vector<int > vht[MN]; set<int > st[MN]; string s; struct Segment {#define ls t[p].lson #define rs t[p].rson struct Node { int lson,rson,val; }t[MN<<9 ]; int tot,rt[MN]; void pushup (int p) t[p].val=max (t[ls].val,t[rs].val); } void modfiy (int &p,int lst,int l,int r,int pos,int v) p=++tot; t[p]=t[lst]; if (l==r){ t[p].val=max (t[p].val,v); return ; } int mid=(l+r)>>1 ; if (mid>=pos) modfiy (ls,t[lst].lson,l,mid,pos,v); else modfiy (rs,t[lst].rson,mid+1 ,r,pos,v); pushup (p); } int query (int p,int l,int r,int fl,int fr) if (l>=fl&&r<=fr){ return t[p].val; } int mid=(l+r)>>1 ,ret=0 ; if (mid>=fl) ret=max (ret,query (ls,l,mid,fl,fr)); if (mid<fr) ret=max (ret,query (rs,mid+1 ,r,fl,fr)); return ret; } #undef ls #undef rs }sg; namespace SA{}using namespace SA; int root (int x) if (pre[x]==x) return pre[x]; else return pre[x]=root (pre[x]); } void merge (int x,int y,int L) int rx=root (x),ry=root (y); if (rx==ry) return ; if (st[rx].size ()<st[ry].size ()) swap (rx,ry); pre[ry]=rx; for (auto p:st[ry]){ auto it=st[rx].lower_bound (p); if (it!=st[rx].end ()){ sg.modfiy (sg.rt[L],sg.rt[L],1 ,n,*it,p); } if (it!=st[rx].begin ()){ it--; sg.modfiy (sg.rt[L],sg.rt[L],1 ,n,p,*it); } } for (auto p:st[ry]) st[rx].insert (p); } int main () cin>>n>>q>>s; getsa (s); for (int i=2 ;i<=n;i++){ vht[ht[i]].push_back (i); } for (int i=1 ;i<=n;i++){ pre[i]=i; st[i].insert (i); } for (int i=n;i>=1 ;i--){ sg.rt[i]=sg.rt[i+1 ]; for (auto p:vht[i]){ merge (sa[p],sa[p-1 ],i); } } while (q--){ int L,R; cin>>L>>R; int l=0 ,r=R-L+1 ; while (l+1 <r){ int mid=(l+r)>>1 ; if (sg.query (sg.rt[mid],1 ,n,L,R-mid+1 )>=L){ l=mid; }else r=mid; } cout<<l<<'\n' ; } return 0 ; }
前面两个都好说,关键字与后面这个每一个区间 LCP 之和怎么求回顾我们后缀数组求解 LCP 的式子:
若r k i < r k j rk_{i}<rk_{j} r k i < r k j ∣ LCP ( i , j ) ∣ = min p = r k i + 1 r k j h t p |\operatorname{LCP}(i,j)|=\min\limits_{p=rk_{i}+1}^{rk_{j}}ht_p ∣ L C P ( i , j ) ∣ = p = r k i + 1 min r k j h t p
那么现在问题转化为求每个区间的区间最小值之和,我们利用单调栈,考虑按排名顺序加入所有后缀并实时维护F ( i ) = ∑ p = 1 i − 1 ∣ LCP ( s a p , s a i ) ∣ F(i)=\sum\limits_{p=1}^{i-1}|\operatorname{LCP}(sa_{p},sa_{i})| F ( i ) = p = 1 ∑ i − 1 ∣ L C P ( s a p , s a i ) ∣ ∑ p = 1 i − 1 min q = p + 1 i h t q \sum\limits_{p=1}^{i-1} \min\limits_{q=p+1}^{i} ht_{q} p = 1 ∑ i − 1 q = p + 1 min i h t q h t i ht_{i} h t i 1 1 1 n ( n + 1 ) ( n − 1 ) 2 − 2 × F ( i ) \dfrac{n(n+1)(n-1)}{2}-2\times F(i) 2 n ( n + 1 ) ( n − 1 ) − 2 × F ( i )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> #define int long long using namespace std;constexpr int MN=1e6 +51 ;int top,sta[MN],L[MN],R[MN],ans;string s; namespace SA{}using namespace SA; signed main () cin>>s; getsa (s); sta[top=1 ]=1 ; for (int i=2 ;i<=len;i++){ while (top&&ht[sta[top]]>ht[i]) R[sta[top--]]=i; L[i]=sta[top]; sta[++top]=i; } while (top) R[sta[top--]]=len+1 ; ans=len*(len-1 )*(len+1 )/2 ; for (int i=2 ;i<=len;i++){ ans-=2 *(R[i]-i)*(i-L[i])*ht[i]; } cout<<ans; return 0 ; }
问题即求:
∑ i = 1 K ∑ j = i + 1 K LCP ( s u f i , s u f j ) \sum_{i=1}^{K} \sum_{j=i+1}^{K} \operatorname{LCP}\left(suf_{i}, suf_{j}\right) i = 1 ∑ K j = i + 1 ∑ K L C P ( s u f i , s u f j )
其中K K K
∑ i = 1 K ∑ j = i + 1 K LCP ( s i , s j ) = ∑ i = 1 K ∑ j = i + 1 K min r i + 1 ≤ k ≤ r j { ht k } \sum_{i=1}^{K} \sum_{j=i+1}^{K} \operatorname{LCP}\left(s_{i}, s_{j}\right)=\sum_{i=1}^{K} \sum_{j=i+1}^{K} \min _{r_{i}+1 \leq k \leq r_{j}}\left\{\text { ht}_{k}\right\} i = 1 ∑ K j = i + 1 ∑ K L C P ( s i , s j ) = i = 1 ∑ K j = i + 1 ∑ K r i + 1 ≤ k ≤ r j min { ht k }
直接单调栈做就可以了,但是记得要去重哦,因为给出的有重复的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <bits/stdc++.h> #define ll long long using namespace std;constexpr int MN=1e6 +15 ;constexpr ll MOD=23333333333333333 ;int n,m,sta[MN],top,a[MN],w[MN],L[MN],R[MN];namespace SA{ int lcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (st[d][i],st[d][j-(1 <<d)+1 ]); } }using namespace SA; bool cmp (int x,int y) return rk[x]<rk[y]; } int main () string s; cin>>n>>m>>s; getsa (s); initst (); while (m--){ int t; ll ans=0 ; cin>>t; for (int i=1 ;i<=t;i++){ cin>>a[i]; } sort (a+1 ,a+1 +t); t=unique (a+1 ,a+1 +t)-a-1 ; sort (a+1 ,a+1 +t,cmp); w[1 ]=0 ; for (int i=2 ;i<=t;i++){ w[i]=lcp (a[i-1 ],a[i]); } sta[top=0 ]=0 ; for (int i=1 ;i<=t;i++){ while (top&&w[sta[top]]>w[i]) top--; L[i]=sta[top]; sta[++top]=i; } sta[top=0 ]=t+1 ; for (int i=t;i>=1 ;i--){ while (top&&w[sta[top]]>=w[i]) top--; R[i]=sta[top]; sta[++top]=i; } for (int i=2 ;i<=t;i++){ ans=(ans+1ll *w[i]*(R[i]-i)%MOD*(i-L[i])%MOD)%MOD; } cout<<ans<<'\n' ; } return 0 ; }
做这个题之前请先解锁:关键点 Trick。
一个序列整体加一个数后与另一个序列相同,其实就是差分数组相同,原因自行思考。
那么源问题去掉限制就是裸的单调栈,但是问题在于要求不相交的,我们可以考虑容斥,总方案数减去相交的方案。总方案单调栈做,问题在于相交如何求解?
但是若求不相交的两个区间信息,请注意在差分数组上求时应当是相隔一个位置。差分数组中相交或相邻的串在原串中都是相交的。
我们考虑相交怎么做,我们可以考虑枚举长度k k k k k k p p p p + k p+k p + k q ≥ p + k − 1 q\ge p+k-1 q ≥ p + k − 1 p p p q q q 1 1 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <bits/stdc++.h> #define int long long #define pir pair<int,int> using namespace std;constexpr int MN=1e6 +15 ;int n,ans,a[MN],b[MN],top,tot;pir st[MN]; struct SA {}A,B; int clac (int x,int y) return (x+y)*(y-x+1 )/2 ; } signed main () vector<int > s,t; cin>>n; --n; for (int i=0 ;i<=n;i++){ cin>>a[i]; } for (int i=n;i>=1 ;i--){ a[i]-=a[i-1 ]; b[++tot]=a[i]; } sort (b+1 ,b+1 +tot); tot=unique (b+1 ,b+1 +tot)-b-1 ; for (int i=1 ;i<=n;i++){ a[i]=lower_bound (b+1 ,b+1 +tot,a[i])-b; s.push_back (a[i]); t.push_back (a[i]); } A.getsa (s); reverse (t.begin (),t.end ()); B.getsa (t); A.initst (); B.initst (); int sum=0 ; for (int i=n;i>=1 ;i--){ ans+=sum; int now=1 ; while (top&&st[top].first>=A.ht[i]){ sum-=st[top].first*st[top].second; now+=st[top--].second; } st[++top]=pir (A.ht[i],now); sum+=now*A.ht[i]; } for (int k=1 ;k<n;k++){ for (int i=1 ;i<=n/k-1 ;i++){ int x1=i*k,y1=x1+k,x2=n-y1+2 ,y2=n-x1+2 ; int lcs=min (k-1 ,B.querylcp (x2,y2)),lcp=A.querylcp (x1,y1); if (lcs+lcp-k+1 <0 ) continue ; ans-=clac (max (lcp-k+1 ,0ll ),lcs+lcp-k+1 ); } } cout<<ans+n*(n+1 )/2 ; return 0 ; }
前面两问都比较好说,问题在于后面的限制,它是两个限制。我们考虑只有一个限制,比如说 LCP 的限制,显然我们可以根据之前我们提到的,并查集的思路,从小往大插,就可以满足LCP ( i , j ) ≤ k 1 \operatorname{LCP}(i,j) \le k1 L C P ( i , j ) ≤ k 1 O ( n log 3 n ) O(n \log^3 n) O ( n log 3 n )
观察LCP ( i , j ) , LCS ( i , j ) \operatorname{LCP}(i,j),\operatorname{LCS}(i,j) L C P ( i , j ) , L C S ( i , j ) LCP ( i , j ) + LCS ( i , j ) − 1 \operatorname{LCP}(i,j)+\operatorname{LCS}(i,j)-1 L C P ( i , j ) + L C S ( i , j ) − 1 ( i − LCP ( i , j ) + 1 , j − LCS ( i , j ) + 1 ) (i-\operatorname{LCP}(i,j)+1,j-\operatorname{LCS}(i,j)+1) ( i − L C P ( i , j ) + 1 , j − L C S ( i , j ) + 1 ) i , j i,j i , j s i − 1 ≠ s j − 1 s_{i-1}\neq s_{j-1} s i − 1 = s j − 1 s [ i , i + LCP ( i , j ) − 1 ] s[i,i+\operatorname{LCP}(i,j)-1] s [ i , i + L C P ( i , j ) − 1 ] f ( x ) = ∑ i = 1 x i ( x − i + 1 ) [ i ≤ k 1 ] [ j ≤ k 2 ] f(x)=\sum\limits_{i=1}^x i(x-i+1)[i \le k1][j\le k2] f ( x ) = i = 1 ∑ x i ( x − i + 1 ) [ i ≤ k 1 ] [ j ≤ k 2 ]
a n s = ∑ 1 ≤ i ≤ j ≤ n [ s i − 1 ≠ s j − 1 ] f ( LCP ( r k i , r k j ) ) = ∑ k = 1 n f ( k ) ∑ 1 ≤ i < j ≤ n [ LCP ( r k i , r k j ) = k , s i − 1 ≠ j − 1 ] = ∑ k = 1 n f ( k ) ∑ 1 ≤ i < j ≤ n [ LCP ( i , j ) = k , s s a i − 1 ≠ s a j − 1 ] \begin{aligned} ans& = \sum_{1\le i \le j \le n}[s_{i-1}\neq s_{j-1}]f(\operatorname{LCP}(rk_i,rk_j)) \\ & = \sum_{k=1}^n f(k)\sum_{1\le i < j \le n}[\operatorname{LCP}(rk_i,rk_j)=k,s_{i-1}\neq _{j-1}] \\ & = \sum_{k=1}^n f(k)\sum_{1\le i < j \le n}[\operatorname{LCP}(i,j)=k,s_{sa_i-1}\neq _{sa_j -1}] \\ \end{aligned} a n s = 1 ≤ i ≤ j ≤ n ∑ [ s i − 1 = s j − 1 ] f ( L C P ( r k i , r k j ) ) = k = 1 ∑ n f ( k ) 1 ≤ i < j ≤ n ∑ [ L C P ( r k i , r k j ) = k , s i − 1 = j − 1 ] = k = 1 ∑ n f ( k ) 1 ≤ i < j ≤ n ∑ [ L C P ( i , j ) = k , s s a i − 1 = s a j − 1 ]
前面和后面都很好处理,中间的 LCP 用单调栈即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #include <bits/stdc++.h> #define int long long #define ull unsigned long long using namespace std;constexpr int MN=1e6 +15 ;int k1,k2,n,st[MN],top,w[MN];ull ans,f[MN]; string s; namespace SA{ int len,sa[MN],x[MN],y[MN],rk[MN],c[MN],ht[MN]; template <typename vct> void getsa (vct &s) { int m=40000 ; len=s.size (); s.insert (s.begin (),0 ); for (int i=1 ;i<=len;i++){ x[i]=s[i]; ++c[x[i]]; } for (int i=1 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=len;i>=1 ;i--) sa[c[x[i]]--]=i; for (int k=1 ;k<=len;k<<=1 ){ int num=0 ; for (int i=len-k+1 ;i<=len;i++) y[++num]=i; for (int i=1 ;i<=len;i++){ if (sa[i]>k) y[++num]=sa[i]-k; } for (int i=1 ;i<=m;i++) c[i]=0 ; for (int i=1 ;i<=len;i++) c[x[i]]++; for (int i=1 ;i<=m;i++) c[i]+=c[i-1 ]; for (int i=len;i>=1 ;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0 ; swap (x,y); num=1 ,x[sa[1 ]]=1 ; for (int i=2 ;i<=len;i++){ if (y[sa[i]]==y[sa[i-1 ]]&&y[sa[i]+k]==y[sa[i-1 ]+k]) x[sa[i]]=num; else x[sa[i]]=++num; } if (num==len) break ; m=num; } for (int i=1 ;i<=len;i++) rk[sa[i]]=i; for (int i=1 ,k=0 ;i<=len;i++){ if (k) k--; int j=sa[rk[i]-1 ]; while (i+k<=len&&j+k<=len&&s[i+k]==s[j+k]) k++; ht[rk[i]]=k; } } } using namespace SA; ull calc1 (int x) { return x*(x+1 )/2 ; } ull calc2 (int x) { return x*(x+1 )*(x+x+1 )/6 ; } ull solve (char lim) { ull cur = 0 , ans = 0 ; top=0 ; memset (w,0 ,sizeof (w)); for (int i = 2 ; i <= n; i++) { int wid = lim ? s[sa[i - 1 ] - 1 ] == lim : 1 ; while (top && st[top] >= ht[i]) { cur -= 1ull * w[top] * f[st[top]]; wid += w[top--]; } st[++top] = ht[i]; w[top] = wid; cur += 1ull * wid * f[ht[i]]; if (lim ? s[sa[i] - 1 ] == lim : 1 ) { ans += cur; } } return ans; } signed main () cin>>s>>k1>>k2; n=s.length (); for (int i=1 ;i<=n;i++){ int l=max (1ll ,i-k2+1 ),r=min (i,k1); if (l>r) break ; f[i]=(calc1 (r)-calc1 (l-1 ))*(i+1 )-(calc2 (r)-calc2 (l-1 )); } getsa (s); ans+=solve (0 ); for (int i=0 ;i<26 ;i++) ans-=solve ('a' +i); cout<<ans; return 0 ; }
CF1073G
[HAOI2016]找相同字符
由于不重合的字符很少,考虑暴力枚举不重合的子串起始位置,让后从这个位置往后跳最长公共前缀的长度,这样如果枚举的位置正确也能保证后续位置也能递推正确。现在问题转化为如何快速求解 LCP,用二分加哈希或 SA 加 ST 表即可实现。
二分加哈希:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <bits/stdc++.h> #define ull unsigned long long using namespace std;constexpr ull base=13131 ;constexpr int MN=1e5 +15 ;int lena,lenb;ull a[MN],b[MN],pw[MN]; string sa,sb; void init () pw[0 ]=1 ; for (int i=1 ;i<MN;i++) pw[i]=pw[i-1 ]*base; } ull hsha (int l,int r) { return a[r]-a[l-1 ]*pw[r-l+1 ]; } ull hshb (int l,int r) { return b[r]-b[l-1 ]*pw[r-l+1 ]; } bool binfind (int x) int st=1 ,r=x+lenb-1 ,ed=lenb; for (int i=1 ;i<=3 ;i++){ int lt=-1 ,rt=ed-st+2 ,ret=0 ; while (lt+1 <rt){ int mid=(lt+rt)>>1 ; if (hsha (x,x+mid-1 )==hshb (st,st+mid-1 )) lt=mid; else rt=mid; } x+=lt+1 ; st+=lt+1 ; if (st>ed) return 1 ; } return hsha (x,x+lenb-st)==hshb (st,ed); } void solve () cin>>sa>>sb; lena=sa.length (),lenb=sb.length (); if (lena<lenb){ cout<<0 <<'\n' ; return ; } sa=" " +sa; sb=" " +sb; for (int i=1 ;i<=lena;i++){ a[i]=a[i-1 ]*base+sa[i]; } for (int i=1 ;i<=lenb;i++){ b[i]=b[i-1 ]*base+sb[i]; } int ans=0 ; for (int i=1 ;i<=lena-lenb+1 ;i++){ if (binfind (i)) ans++; } cout<<ans<<'\n' ; } int main () init (); int T; cin>>T; while (T--){ solve (); } return 0 ; }
SA:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int n,m;string s,t; namespace SA{ int lcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (st[d][i],st[d][j-(1 <<d)+1 ]); } }using namespace SA; void solve () cin>>s>>t; n=s.length (),m=t.length (); s=" " +s,t=" " +t; string sst; for (int i=1 ;i<=n;i++){ sst.push_back (s[i]); } sst.push_back ('#' ); for (int i=1 ;i<=m;i++){ sst.push_back (t[i]); } getsa (sst); initst (); int ret=0 ; for (int i=1 ;i<=n-m+1 ;i++){ int curs=i,curt=1 ; for (int j=1 ;j<=4 ;j++){ if (curt<=m){ int lcpl=lcp (curs,curt+n+1 ); curs+=lcpl+(j<4 ); curt+=lcpl+(j<4 ); } } ret+=curt>m; } cout<<ret<<'\n' ; } int main () int T; cin>>T; while (T--){ solve (); } return 0 ; }
2.2 有讲两种做法。
现在我们要求在主串T T T S S S T T T S S S T T T T T T S S S S S S O ( ∣ S ∣ ) O(|S|) O ( ∣ S ∣ ) O ( ∣ S ∣ log ∣ T ∣ ) O(|S| \log |T|) O ( ∣ S ∣ log ∣ T ∣ ) T T T
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <bits/stdc++.h> using namespace std;constexpr int MN=3e6 +15 ;int col[MN],vis[MN],L[MN],R[MN],sum,tot,ans;string s,str; deque<int > q; namespace SA{}using namespace SA; void add (int x) if (col[x]==0 ) return ; vis[col[x]]++; if (vis[col[x]]==1 ) sum++; } void del (int x) if (col[x]==0 ) return ; vis[col[x]]--; if (vis[col[x]]==0 ) sum--; } int main () while (cin>>s){ tot++; L[tot]=str.length ()+1 ; str=str+s; R[tot]=str.length (); str.push_back (tot); } getsa (str); for (int i=1 ;i<=tot;i++){ for (int j=L[i];j<=R[i];j++){ col[rk[j]]=i; } } add (1 ); for (int r=2 ,l=1 ;r<=len;r++){ while (!q.empty ()&&ht[q.back ()]>=ht[r]) q.pop_back (); q.push_back (r); add (r); if (sum==tot){ while (tot==sum&&l<r) del (l++); add (--l); } while (!q.empty ()&&q.front ()<=l) q.pop_front (); if (tot==sum) ans=max (ans,ht[q.front ()]); } cout<<ans; return 0 ; }
把字符串加分隔符连接在一起,让后跑后缀数组求h t ht h t O ( n m ) O(nm) O ( n m )
考虑计算 LCP 的过程就是一段h t ht h t h t ht h t
放这个题就是为了看见 SA 不要僵化思路,这种一般是学多做题多了导致的 www。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;constexpr int MN=3e6 +15 ,MK=55 ;int n,pos[MN],minn[MK],ans[MK][MK];vector<int > str; namespace SA{}using namespace SA; int main () cin>>n; for (int i=1 ;i<=n;i++){ string s; cin>>s; for (auto c:s){ str.push_back (c); pos[str.size ()]=i; } str.push_back (1000 +i); } getsa (str); for (int i=2 ;i<=len;i++){ for (int j=1 ;j<=n;j++) minn[j]=min (minn[j],ht[i]); minn[pos[sa[i-1 ]]]=ht[i]; for (int j=1 ;j<=n;j++){ ans[pos[sa[i]]][j]=ans[j][pos[sa[i]]]=max (ans[pos[sa[i]]][j],minn[j]); } } for (int i=1 ;i<=n;i++){ for (int j=1 ;j<=n;j++){ if (i!=j) cout<<ans[i][j]<<" " ; } cout<<'\n' ; } return 0 ; }
一个序列整体加一个数后与另一个序列相同,其实就是差分数组相同,原因自行思考。
但是若求不相交的两个区间信息,请注意在差分数组上求时应当是相隔一个位置。差分数组中相交或相邻的串在原串中都是相交的。
那么先求差分数组,让后两个差分数组中间加分隔符连起来建立 SA,让后问题转化为求所有子串最长公共子串,考虑二分,只要有n n n ≥ L \ge L ≥ L h t ht h t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int n,lenn[MN],sta[MN],top,a[1145 ][1145 ];int pos[MN];bool vis[MN];string s; namespace SA{ }using namespace SA; bool check (int x) while (top) vis[sta[top--]]=0 ; for (int i=1 ;i<=len;i++){ if (ht[i]<x) while (top) vis[sta[top--]]=0 ; if (!vis[pos[sa[i]]]){ vis[pos[sa[i]]]=1 ; sta[++top]=pos[sa[i]]; if (top==n) return 1 ; } } return 0 ; } int main () cin>>n; int l=0 ,r=1e6 ,ans=0 ; for (int i=1 ;i<=n;i++){ cin>>lenn[i]; for (int j=1 ;j<=lenn[i];j++){ cin>>a[i][j]; } r=min (r,lenn[i]-1 ); } for (int i=1 ;i<=n;i++){ for (int j=2 ;j<=lenn[i];j++){ s.push_back (a[i][j]-a[i][j-1 ]); pos[s.length ()]=i; } s.push_back ('#' ); } getsa (s); while (l<=r){ int mid=(l+r)>>1 ; if (check (mid)){ l=mid+1 ; ans=mid; }else r=mid-1 ; } cout<<ans+1 ; return 0 ; }
划分为 2 个子问题:
第一问我们不说,我们考虑第二问如何求解,我们可以对于h t ht h t l e n len l e n
结合起来就可以啦,时间复杂度O ( S log S ) O(S \log S) O ( S log S ) S = ∑ ∣ s i ∣ S=\sum\limits|s_{i}| S = ∑ ∣ s i ∣
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include <bits/stdc++.h> using namespace std;constexpr int MN=2e6 +15 ;int n,L[MN],R[MN];string s; vector<int > vct; namespace SA{ void clear () memset (sa,0 ,sizeof (sa)); memset (rk,0 ,sizeof (rk)); memset (ork,0 ,sizeof (ork)); memset (buc,0 ,sizeof (buc)); memset (id,0 ,sizeof (id)); memset (ht,0 ,sizeof (ht)); memset (st,0 ,sizeof (st)); } }using namespace SA; bool check (int x) vct.clear (); for (int i=1 ;i<=len;i++){ if (ht[i]<x){ bool flag=true ; for (int j=1 ;j<=n;j++){ int mn=MN,mx=0 ; for (int p:vct){ if (p<L[j]||p>R[j]) continue ; mn=min (mn,p); mx=max (mx,p); } if (mx-mn<x){ flag=false ; break ; } } if (flag) return true ; vct.clear (); } vct.push_back (sa[i]); } bool flag=true ; for (int j=1 ;j<=n;j++){ int mn=MN,mx=0 ; for (int p:vct){ if (p<L[j]||p>R[j]) continue ; mn=min (mn,p); mx=max (mx,p); } if (mx-mn<x){ flag=false ; break ; } } return flag; } void solve () cin>>n; s.clear (); for (int i=1 ;i<=n;i++){ string st; cin>>st; L[i]=s.length ()+1 ; R[i]=s.length ()+st.length (); s+=st; s.push_back ('#' ); } getsa (s); int l=1 ,r=len,ans=0 ; while (l<=r){ int mid=(l+r)>>1 ; if (check (mid)) ans=mid,l=mid+1 ; else r=mid-1 ; } cout<<ans<<'\n' ; } int main () ios::sync_with_stdio (0 );cin.tie (0 ); int T;cin>>T; while (T--) solve (); return 0 ; }
第一眼看上去好像没什么思路啊 www。考虑发掘性质,从大到小的话,如果我们选取的子串在不断扩大的话,排名会逐渐下降,但重要度因为是求和,所以是单调不减,我们考虑利用冰火战士 的思路,两次二分出这个排名和重要度之和的交点,让后我们检查是否符合要求。
现在问题在于如何求某个子串在所有字符串本质不同子串的排名。所有本质不同子串的计算我们之前提到过,也就是:( ∑ i = 1 ∣ S ∣ n − p i + 1 ) − ( ∑ i = 1 ∣ S ∣ − 1 ∣ LCP ( p i , p i + 1 ) ∣ ) \left( \sum\limits_{i=1}^{|S|} n-p_{i}+1 \right)-\left(\sum\limits_{i=1}^{|S|-1} |\operatorname{LCP}(p_{i},p_{i+1})| \right) ( i = 1 ∑ ∣ S ∣ n − p i + 1 ) − ( i = 1 ∑ ∣ S ∣ − 1 ∣ L C P ( p i , p i + 1 ) ∣ ) s , t s,t s , t t t t s s s t t t s s s
两个条件,第一个条件对应的后缀排名是一段排名区间[ L , R ] , ( L ≤ r k l ≤ R ) [L,R],(L\le rk_{l}\le R) [ L , R ] , ( L ≤ r k l ≤ R ) [ R + 1 , n ] [R+1,n] [ R + 1 , n ] [ L , n ] [L,n] [ L , n ] r − l r-l r − l L L L r k l rk_{l} r k l [ L , r k l ] [L,rk_{l}] [ L , r k l ] r − l + 1 r-l+1 r − l + 1 O ( n log 2 n ) O(n \log^2 n) O ( n log 2 n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <bits/stdc++.h> #define int long long #define pir pair<int,int> using namespace std;constexpr int MN=1e6 +15 ;int n,v[MN],sumh[MN],sumsa[MN];vector<pir> ans; string s; namespace SA{ int querylcp (int i,int j) int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (ST[d][l],ST[d][r-(1 <<d)+1 ]); } }using namespace SA; int clac (int x,int y) int l=1 ,r=x=rk[x]+1 ; while (l+1 <r){ int mid=(l+r)>>1 ; if (querylcp (mid,x)>=y) r=mid; else l=mid; } return sumsa[l]-sumh[l+1 ]-y+1 ; } signed main () cin>>s; n=s.length (); for (int i=1 ;i<=n;i++){ cin>>v[i]; } getsa (s); initst (); for (int i=n;i>=1 ;i--){ sumh[i]=sumh[i+1 ]+ht[i]; sumsa[i]=sumsa[i+1 ]+n-sa[i]+1 ; } for (int i=1 ;i<=n;i++) v[i]+=v[i-1 ]; for (int i=1 ;i<=n;i++){ int l=1 ,r=n-i+2 ; while (l+1 <r){ int mid=(l+r)>>1 ; if (clac (i,mid)>=v[i+mid-1 ]-v[i-1 ]) l=mid; else r=mid; } if (clac (i,l)==v[i+l-1 ]-v[i-1 ]){ ans.push_back (pir (i,i+l-1 )); } } cout<<ans.size ()<<'\n' ; for (auto p:ans) cout<<p.first<<" " <<p.second<<'\n' ; return 0 ; }
P4081 [USACO17DEC] Standing Out from the Herd P
P6640 [BJOI2020] 封印
P2408 不同子串
P5431
显然 AABB 由两个形如 AA 的串拼接起来的,考虑维护两个数组a i , b i a_{i},b_{i} a i , b i a i a_{i} a i i i i b i b_{i} b i i i i a n s = ∑ i = 1 n − 1 a i b i + 1 ans=\sum\limits_{i=1}^{n-1}a_{i}b_{i+1} a n s = i = 1 ∑ n − 1 a i b i + 1
现在问题在于如何求解a i , b i a_{i},b_{i} a i , b i 枚举长度,设置关键点 求解a , b a,b a , b
对于固定的L L L L L L L C S + L C P ≥ l e n LCS+LCP\ge len L C S + L C P ≥ l e n l e n len l e n l e n len l e n l e n len l e n O ( n log 2 n ) O(n\log^2 n) O ( n log 2 n )
从这道题开始,设置关键点变成了经典套路。
下列代码f → a , g → b f\to a,g\to b f → a , g → b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int T,f[MN],g[MN];string s; struct SA { int len,sa[MN],x[MN],y[MN],rk[MN],c[MN],ht[MN],ST[30 ][MN]; void initst () for (int i=1 ;i<30 ;i++){ for (int j=1 ;j+(1 <<i)-1 <=len;j++){ ST[i][j]=min (ST[i-1 ][j],ST[i-1 ][j+(1 <<(i-1 ))]); } } } int querylcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (ST[d][l],ST[d][r-(1 <<d)+1 ]); } }A,B; void solve () cin>>s; int n=s.length (); A.getsa (s); A.initst (); reverse (s.begin (),s.end ()); B.getsa (s); B.initst (); for (int i=1 ;i<=n;i++){ f[i]=g[i]=0 ; } for (int len=1 ;len<=(n>>1 );len++){ for (int l=len;l<=n;l+=len){ int r=l+len,lcp=min (len,A.querylcp (l,r)),lcs=min (len-1 ,B.querylcp (n-(l-1 )+1 ,n-(r-1 )+1 )); if (lcp+lcs>=len){ int cov=lcp+lcs-len+1 ; f[r+lcp-cov]++; f[r+lcp]--; g[l-lcs+cov]--; g[l-lcs]++; } } } for (int i=1 ;i<=n;i++) f[i]+=f[i-1 ],g[i]+=g[i-1 ]; long long ans=0 ; for (int i=1 ;i<n;i++) ans+=1ll *f[i]*g[i+1 ]; cout<<ans<<'\n' ; } int main () cin>>T; while (T--){ solve (); } return 0 ; }
借助上面的套路,考虑枚举循环节长度L L L L L L k k k k k k k k k
我们考虑二分k k k k k k p , p + L , p + 2 × L , … , p + ( k − 1 ) L p,p+L,p+2\times L,\dots,p+(k-1)L p , p + L , p + 2 × L , … , p + ( k − 1 ) L L L L L C S + L C P − 1 ≥ L LCS+LCP-1\ge L L C S + L C P − 1 ≥ L k k k O ( n log 2 n ) O(n \log^2 n) O ( n log 2 n )
还可以更优化,我们当L L L O ( n log n ) O(n \log n) O ( n log n )
Alex_wei 的 Sol 3 看不懂 Orz。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <bits/stdc++.h> using namespace std;constexpr int MN = 5e4 + 5 ;int n;struct SA { int len, sa[MN], x[MN], y[MN], rk[MN], c[MN], ht[MN], ST[16 ][MN]; int querylcp (int i, int j) if ((i = rk[i]) > (j = rk[j])) swap (i, j); int d = __lg(j - (i++)); return min (ST[d][i], ST[d][j - (1 << d) + 1 ]); } } A, B; void solve () cin >> n; string str; for (int i = 1 ; i <= n; i++) { char x; cin >> x; str.push_back (x); } A.getsa (str); A.initst (); reverse (str.begin (), str.end ()); B.getsa (str); B.initst (); int ans = 1 ; for (int len = 1 ; len <= n; len++) { for (int l = len, r = len + len; r <= n; l += len, r += len) { int lcp = A.querylcp (l, r); int lcs = B.querylcp (n - r + 1 , n - l + 1 ); ans = max (ans, (lcp + lcs - 1 ) / len + 1 ); } } cout << ans << '\n' ; } int main () ios::sync_with_stdio (false ); cin.tie (nullptr ); int T; cin >> T; while (T--) { solve (); } return 0 ; }
这里我们是单独介绍一些利用贪心思路和 DP 思路求解的问题。一般来说,这里的问题 SA 不是主角,是起到一个打辅助的作用的。
一个显然的贪心,我们在新选择一个字符串并起来的时候应当尽可能的进行匹配,我们一定会匹配到第一个k k k s i + k ≠ t j + k s_{i+k} \neq t_{j+k} s i + k = t j + k
字符串匹配,之前做过一堆 KMP 的题,这里肌肉记忆设f ( i , j ) f(i,j) f ( i , j ) s s s i i i t t t j j j x ≤ 30 x\le 30 x ≤ 3 0 f ( i , j ) f(i,j) f ( i , j ) s s s i i i j j j t t t f ( i , j ) f(i,j) f ( i , j ) f ( i + 1 , j ) f(i+1,j) f ( i + 1 , j ) s [ i + 1 , n ] s[i+1,n] s [ i + 1 , n ] t [ f ( i , j − 1 ) + 1 , m ] t[f(i,j-1)+1,m] t [ f ( i , j − 1 ) + 1 , m ] L L L f ( i + L , j ) ← max ( f ( i + L , j ) , f ( i , j − 1 ) + L ) f(i+L,j) \leftarrow \max(f(i+L,j),f(i,j-1)+L) f ( i + L , j ) ← max ( f ( i + L , j ) , f ( i , j − 1 ) + L ) O ( n x + n log n ) O(nx+n \log n) O ( n x + n log n )
DP 加贪心加 SA,很好的题啊!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <bits/stdc++.h> using namespace std;constexpr int MN=2e5 +15 ,MK=35 ;int f[MN][MK],X,n,m;string s,t,sst; namespace SA{ int lcp (int i,int j) if ((i=rk[i])>(j=rk[j])) swap (i,j); int d=__lg(j-(i++)); return min (st[d][i],st[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (st[d][l],st[d][r-(1 <<d)+1 ]); } }using namespace SA; int lcpst (int i,int j) if (i>n||j>m) return 0 ; j+=n+1 ; return lcp (i,j); } int main () cin>>n>>s>>m>>t; sst=s+'#' +t; getsa (sst); initst (); cin>>X; for (int i=1 ;i<=n;i++){ for (int j=1 ;j<=X;j++){ int L=lcpst (i,f[i][j-1 ]+1 ); f[i+L][j]=max (f[i+L][j],f[i][j-1 ]+L); f[i+1 ][j]=max (f[i+1 ][j],f[i][j]); } } if (f[n+1 ][X]==m) cout<<"YES" ; else cout<<"NO" ; return 0 ; }
有一个贪心的想法就是我们贪心让最大位数最小。那么答案串的长度最多就是L = ⌈ n k ⌉ L=\lceil \dfrac{n}{k} \rceil L = ⌈ k n ⌉ ⌈ n k ⌉ \lceil \dfrac{n}{k} \rceil ⌈ k n ⌉ ⌈ n k ⌉ \lceil \dfrac{n}{k} \rceil ⌈ k n ⌉ ⌈ n k ⌉ − 1 \lceil \dfrac{n}{k} \rceil-1 ⌈ k n ⌉ − 1
让后我们考虑如何比较字符串大小,考虑二分排名r k rk r k i i i ⌈ n k ⌉ / ⌈ n k ⌉ − 1 \lceil \dfrac{n}{k} \rceil / \lceil \dfrac{n}{k} \rceil-1 ⌈ k n ⌉ / ⌈ k n ⌉ − 1 i i i
最后要求输出最大值数字串,考虑存下排名的值输出这个排名的后缀长为⌈ n k ⌉ \lceil \dfrac{n}{k} \rceil ⌈ k n ⌉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <bits/stdc++.h> #define int long long using namespace std;constexpr int MN=1e6 +15 ;int n,K;string s; namespace SA{}using namespace SA; bool check (int mid) int len=n/K; for (int i=1 ;i<=len;i++){ int st=i,cnt=0 ; for (int j=1 ;j<=K;j++){ if (cnt<(n%K)&&rk[st]<=mid){ st+=len+1 ; cnt++; }else st+=len; } if (st-i==n) return 1 ; } return 0 ; } signed main () cin>>n>>K>>s; if (n%K==0 ){ cout<<8 ; return 0 ; } s=s+s; getsa (s); int l=1 ,r=2 *n; while (l+1 <r){ int mid=(l+r)>>1 ; if (check (mid)) r=mid; else l=mid; } for (int i=1 ;i<=ceil (n*1.0 /K);i++){ cout<<s[sa[l]+i-1 ]; } return 0 ; }
先解决如何查一个查询串是多少个模板串的子串。我们考虑将所有模板串用分隔符连接起来跑 SA,那么查询串是一个模板串的子串,在 SA 上的范围表示的是一个区间的形式,这个区间的性质表示为LCP ( s i , s j ) = l e n \operatorname{LCP}(s_{i},s_{j})=len L C P ( s i , s j ) = l e n
让后第二个,查询区间颜色数,既然我们已经有了每一个查询串对应的 SA 区间,考虑莫队维护区间颜色数,让后就做完了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;struct Query { int l,r,id; }qry[MN]; int n,m,qtot,qlen,col[MN],sumc,cnt[MN],ans[MN];vector<int > str; namespace SA{ int querylcp (int i,int j) int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (ST[d][l],ST[d][r-(1 <<d)+1 ]); } }using namespace SA; bool cmp (Query x,Query y) if (x.l/qlen!=y.l/qlen) return x.l<y.l; return x.r<y.r; } void add (int x) cnt[col[x]]++; if (cnt[col[x]]==1 ) sumc++; } void del (int x) cnt[col[x]]--; if (!cnt[col[x]]) sumc--; } int main () cin>>n>>m; for (int i=1 ;i<=n;i++){ string s; cin>>s; for (auto c:s){ str.push_back (c); col[str.size ()]=i; } str.push_back ('z' +i); } getsa (str); for (int i=1 ;i<=m;i++){ int slen,L=1 ,R=len; string s; cin>>s; slen=s.length (); s=" " +s; for (int j=1 ;j<=slen;j++){ int l=L,r=R; while (l<=r){ int mid=(l+r)>>1 ; if (str[sa[mid]+j-1 ]<s[j]) l=mid+1 ; else r=mid-1 ; } swap (l,L); r=R; while (l<=r){ int mid=(l+r)>>1 ; if (str[sa[mid]+j-1 ]<=s[j]) l=mid+1 ; else r=mid-1 ; } R=r; } if (L<=R){ qry[++qtot]={L,R,i}; } } qlen=sqrt (len); sort (qry+1 ,qry+1 +qtot,cmp); int l=1 ,r=0 ; for (int i=1 ;i<=qtot;i++){ while (l<qry[i].l) del (sa[l++]); while (l>qry[i].l) add (sa[--l]); while (r<qry[i].r) add (sa[++r]); while (r>qry[i].r) del (sa[r--]); ans[qry[i].id]=sumc; } for (int i=1 ;i<=m;i++) cout<<ans[i]<<'\n' ; return 0 ; }
哈哈其实没有那么多啦,我实现的时候其实也就不到 300 行吧,其实就是板子加板子,只是不过我是晚上写的太困了调了一万年。
因为信息具有可减性,战术将询问差分扫描线,即Q ( u , v , l , r ) Q(u,v,l,r) Q ( u , v , l , r ) Q ( u , v , 1 , r ) − Q ( u , v , 1 , l − 1 ) Q(u,v,1,r)-Q(u,v,1,l-1) Q ( u , v , 1 , r ) − Q ( u , v , 1 , l − 1 )
对于后缀数组,查一个查询串是多少个模板串的子串。我们考虑将所有模板串用分隔符连接起来跑 SA,那么查询串是一个模板串的子串,在 SA 上的范围表示的是一个区间的形式,这个区间的性质表示为LCP ( s i , s j ) = l e n \operatorname{LCP}(s_{i},s_{j})=len L C P ( s i , s j ) = l e n
那么对于本题来说也是一样的,我们对s i s_i s i p p p s 1 → p s_{1\to p} s 1 → p Q ( u , v , 1 , p ) Q(u,v,1,p) Q ( u , v , 1 , p ) u → v u\to v u → v t ( u , v ) t(u,v) t ( u , v ) k k k t ( u , v ) t(u,v) t ( u , v ) k k k s s s s , t s,t s , t t t t s s s t t t s s s
但是本题上树了,我们必须要考虑哈希求解,那么这样的话我们必须求解出s [ 1 → l e n ] s[1\to len] s [ 1 → l e n ] u → v u\to v u → v l e n len l e n O ( q log 3 n ) O(q \log^3 n) O ( q log 3 n ) O ( q log 2 n ) O(q \log^2 n) O ( q log 2 n )
巨大码农,代码 。
又是最长公共子串,好烦啊~
直接二分长度,让后问题转化为判定性问题,那么一个长度可行当且仅当:
开头在[ a , b − m i d + 1 ] [a,b-mid+1] [ a , b − m i d + 1 ] LCP(s,c) ≥ m i d \operatorname{LCP(s,c)}\ge mid L C P ( s , c ) ≥ m i d c c c s [ c → d ] s[c\to d] s [ c → d ] 那么问题转化为询问满足以上两个条件的后缀s u f k suf_{k} s u f k 0 0 0
我主席树又写错了,希望大家认真实现,我已经做麻了呜呜呜。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 #include <bits/stdc++.h> #define int long long using namespace std;constexpr int MN=1e6 +15 ;int n,m;string s; struct Segment {#define ls t[p].lson #define rs t[p].rson struct Node { int lson,rson,val; }t[MN*20 +1145 ]; int rt[MN],tot; int insert (int lst,int l,int r,int x) int p=++tot; t[p]=t[lst]; t[p].val++; if (l==r) return p; int mid=(l+r)>>1 ; if (x<=mid) t[p].lson=insert (t[lst].lson,l,mid,x); else t[p].rson=insert (t[lst].rson,mid+1 ,r,x); return p; } int query (int u,int v,int l,int r,int fl,int fr) if (l>=fl&&r<=fr){ return t[v].val-t[u].val; } int mid=(l+r)>>1 ,ret=0 ; if (mid>=fl) ret+=query (t[u].lson,t[v].lson,l,mid,fl,fr); if (mid<fr) ret+=query (t[u].rson,t[v].rson,mid+1 ,r,fl,fr); return ret; } int query (int u,int v,int l,int r) return query (rt[u-1 ],rt[v],1 ,n,l,r); } #undef ls #undef rs }sg; namespace SA{ int len,sa[MN],x[MN],y[MN],rk[MN],c[MN],ht[MN],ST[30 ][MN]; void initst () for (int i=1 ;i<30 ;i++){ for (int j=1 ;j+(1 <<i)-1 <=len;j++){ ST[i][j]=min (ST[i-1 ][j],ST[i-1 ][j+(1 <<(i-1 ))]); } } } int querylcp (int i,int j) int d=__lg(j-(i++)); return min (ST[d][i],ST[d][j-(1 <<d)+1 ]); } int queryst (int l,int r) int d=__lg(r-l+1 ); return min (ST[d][l],ST[d][r-(1 <<d)+1 ]); } }using namespace SA; bool check (int x,int a,int b,int c) int l=1 ,r=rk[c],L,R; while (l<r){ int mid=(l+r)>>1 ; if (querylcp (mid,rk[c])<x) l=mid+1 ; else r=mid; } L=r; l=rk[c],r=n; while (l<r){ int mid=(l+r+1 )>>1 ; if (querylcp (rk[c],mid)<x) r=mid-1 ; else l=mid; } R=r; return sg.query (L,R,a,b-x+1 )>0 ; } void solve (int a,int b,int c,int d) int l=0 ,r=min (b-a+1 ,d-c+1 ); while (l<r){ int mid=(l+r+1 )>>1 ; if (check (mid,a,b,c)) l=mid; else r=mid-1 ; } cout<<r<<'\n' ; } signed main () cin>>n>>m>>s;; getsa (s); initst (); for (int i=1 ;i<=n;i++){ sg.rt[i]=sg.insert (sg.rt[i-1 ],1 ,n,sa[i]); } while (m--){ int a,b,c,d; cin>>a>>b>>c>>d; solve (a,b,c,d); } return 0 ; }
将姓和名用分隔符连接,问题相当于给定 n n n m m m
将所有文本串用分隔符后建后缀数组,对每个模式串求出以其为前缀的排名区间,这个讲过 100 万遍了不再重复。第一位就是问区间颜色数,考虑离线下来跑莫队或者扫描线 BIT,第二问相当于对每种颜色查询与其有交的区间数。对每个区间和每个颜色在第一个位置统计答案,则每个位置对其颜色贡献在左端点落一个区间,右端点落另一端区间的区间数量,这是二位数点,还是扫描线 BIT。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #include <bits/stdc++.h> using namespace std;constexpr int N=1e6 +15 , INF=1e9 ;int nn, q, n, m=400000 ;int sa[N], ra[N], h[N], t1[N], t2[N], c[N];int st[20 ][N], lg[N];int s[N], col[N], hd[N], len[N], bu[N];int pre[N], ans1[N], ans2[N];int lp[N]; struct Query { int id, l, r; } qry[N];struct BIT { int t[N]; void clear () memset (t, 0 , sizeof (t)); } void upd (int i, int v) if (i) for (; i<=n; i+=i&-i) t[i] += v; } int query (int i) int res = 0 ; for (; i; i-=i&-i) res += t[i]; return res; } int query (int l, int r) return query (r) - query (l-1 ); } } bit1, bit2; void getsa () } void geth () } void initST () } int getmin (int a, int b) if (a == b) return INF; if (a > b) swap (a, b); int d = lg[b-(a++)]; return min (st[d][a], st[d][b-(1 <<d)+1 ]); } bool cmp (Query a, Query b) return a.r < b.r; } int main () ios::sync_with_stdio (0 ); cin.tie (0 ); cin >> nn >> q; int x, c = 10000 ; for (int i=1 ; i<=nn; ++i) { for (int j=0 ; j<2 ; ++j) { int len; cin >> len; while (len--) { cin >> x; s[++n] = x; col[n] = i; } s[++n] = ++c; } } for (int i=1 ; i<=q; ++i) { cin >> len[n+1 ]; hd[n+1 ] = i; for (int j=len[n+1 ]; j--; ) { cin >> x; s[++n] = x; col[n] = -i; } s[++n] = ++c; } getsa (); geth (); initST (); for (int i=1 ; i<=n; ++i) { if (col[sa[i]] > 0 ) { pre[i] = bu[col[sa[i]]]; bu[col[sa[i]]] = i; } if (hd[i]) { qry[hd[i]].id = hd[i]; int l=1 , r=ra[i]; while (l < r) { int mi = (l+r)>>1 ; if (getmin (mi, ra[i]) >= len[i]) r = mi; else l = mi+1 ; } qry[hd[i]].l = lp[hd[i]] = l; l = ra[i], r = n; while (l < r) { int mi = (l+r+1 )>>1 ; if (getmin (ra[i], mi) >= len[i]) l = mi; else r = mi-1 ; } qry[hd[i]].r = r; } } sort (qry+1 , qry+q+1 , cmp); sort (lp+1 , lp+q+1 ); for (int i=1 , j=1 , k=1 ; i<=n; ++i) { for (; j<=q && lp[j]==i; ++j) bit2. upd (i, 1 ); if (col[sa[i]] > 0 ) { ans2[col[sa[i]]] += bit2. query (i) - bit2. query (pre[i]); bit1. upd (i, 1 ); bit1. upd (pre[i], -1 ); } for (; k<=q && qry[k].r==i; ++k) { ans1[qry[k].id] = bit1. query (qry[k].l, qry[k].r); bit2. upd (qry[k].l, -1 ); } } for (int i=1 ; i<=q; ++i) cout << ans1[i] << "\n" ; for (int i=1 ; i<=nn; ++i) cout << ans2[i] << " " ; return 0 ; }
关键性质:位运算在每一位独立。
设f ( i , d ) f(i,d) f ( i , d ) s s s i i i 2 d 2^d 2 d f ( i , d + 1 ) = f ( i , d ) + f ( i ⊕ 2 d , d ) f(i,d+1)=f(i,d)+f(i\oplus 2^d,d) f ( i , d + 1 ) = f ( i , d ) + f ( i ⊕ 2 d , d ) r k ( i , d ) rk(i,d) r k ( i , d ) f ( i , d ) f(i,d) f ( i , d ) f ( j , d ) ( 0 ≤ j ≤ 2 n ) f(j,d)(0\le j \le 2^n) f ( j , d ) ( 0 ≤ j ≤ 2 n ) p ( i , d + 1 ) p(i,d+1) p ( i , d + 1 ) ( p ( i , d ) , p ( i ⊕ 2 d , d ) ) (p(i,d),p(i\oplus 2^d ,d)) ( p ( i , d ) , p ( i ⊕ 2 d , d ) ) ( p ( j , d ) , p ( j ⊕ 2 d , d ) ) (p(j,d),p(j \oplus 2^d,d)) ( p ( j , d ) , p ( j ⊕ 2 d , d ) )
倍增计数排序O ( 2 n n ) O(2^n n) O ( 2 n n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int n,m,v,a[MN],b[MN],c[MN];string s; bool cmp (int x,int y) if (b[x]==b[y]) return b[x^v]<b[y^v]; return b[x]<b[y]; } int main () cin>>n>>s; m=1 <<n; for (int i=0 ;i<m;i++) a[i]=i,b[i]=s[i]-'a' ; sort (a,a+m,cmp); for (int i=1 ;i<=n;i++){ v=(1 <<(i-1 )); sort (a,a+m,cmp); int cnt=0 ; for (int j=0 ;j<m;j++){ if (j==0 ||cmp (a[j-1 ],a[j])) c[a[j]]=++cnt; else c[a[j]]=cnt; } for (int j=0 ;j<m;j++) b[j]=c[j]; } for (int i=0 ;i<m;i++) cout<<s[i^a[0 ]]; }
给同学做了,好题。
给出 SA 数组和 Height 数组我们能得到什么信息,具体来说:
对于2 ≤ i ≤ n 2\le i \le n 2 ≤ i ≤ n s [ s a i − 1 ] ≤ s [ s a i ] s[sa_{i-1}]\le s[sa_{i}] s [ s a i − 1 ] ≤ s [ s a i ] r k s a ( i − 1 ) + 1 > r k s a ( i ) + 1 rk_{sa(i-1)+1}>rk_{sa(i)+1} r k s a ( i − 1 ) + 1 > r k s a ( i ) + 1 s [ s a i − 1 ] < s [ s a i ] s[sa_{i-1}] < s[sa_{i}] s [ s a i − 1 ] < s [ s a i ] 对于2 ≤ i ≤ n 2\le i \le n 2 ≤ i ≤ n 0 ≤ j ≤ h t i 0\le j \le ht_{i} 0 ≤ j ≤ h t i s [ s a i − 1 + j ] ≤ s [ s a i + j ] s[sa_{i-1}+j]\le s[sa_{i}+j] s [ s a i − 1 + j ] ≤ s [ s a i + j ] s a i − 1 + h t i ≤ n sa_{i-1}+ht_{i}\le n s a i − 1 + h t i ≤ n s [ s a i − 1 + h t i ] < s [ s a i + h t i ] s[sa_{i-1}+ht_{i}] < s[sa_{i}+ht_{i}] s [ s a i − 1 + h t i ] < s [ s a i + h t i ] 对于h t i ≠ − 1 ht_{i}\neq -1 h t i = − 1 j ∈ [ 0 , h t i ) j\in [0,ht_{i}) j ∈ [ 0 , h t i ) s [ s a i + j ] = s [ s a i + 1 + j ] s[sa_{i}+j]=s[sa_{i+1}+j] s [ s a i + j ] = s [ s a i + 1 + j ] s [ s a i + h t i ] < s [ s a i + 1 + h t i ] s[sa_{i}+ht_{i}]<s[sa_{i+1}+ht_{i}] s [ s a i + h t i ] < s [ s a i + 1 + h t i ]
现在考虑h t i = − 1 ht_{i}=-1 h t i = − 1 s a i , s a i + 1 sa_{i},sa_{i+1} s a i , s a i + 1 s u f s a ( i ) < s u f s a ( i + 1 ) suf_{sa(i)}<suf_{sa(i+1)} s u f s a ( i ) < s u f s a ( i + 1 ) s [ s a i ] , s [ s a i + 1 ] s[sa_{i}],s[sa_{i+1}] s [ s a i ] , s [ s a i + 1 ] r k ( s a i + 1 ) < r k ( s a i + 1 + 1 ) rk(sa_{i}+1)<rk(sa_{i+1}+1) r k ( s a i + 1 ) < r k ( s a i + 1 + 1 ) s [ s a i ] s[sa_i] s [ s a i ] s [ s a i + 1 ] s[sa_{i+1}] s [ s a i + 1 ] s [ s a i ] s[sa_i] s [ s a i ] s [ s a i + 1 ] s[sa_{i+1}] s [ s a i + 1 ] O ( n 2 ) O(n^2) O ( n 2 )
进一步可以发现,只要在合并的时候保持后缀大小顺序的连边,就可以通过了。时间复杂度O ( n log n ) O(n \log n) O ( n log n ) O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;constexpr int MN=5200 ;int n,sa[MN],rk[MN],pre[MN],ht[MN];char ans[MN];vector<int > G[MN]; int root (int x) if (pre[x]==x) return pre[x]; else return pre[x]=root (pre[x]); } int main () cin>>n; for (int i=1 ;i<=n;i++){ cin>>sa[i]; rk[sa[i]]=i; pre[i]=i; } for (int i=2 ;i<=n;i++){ cin>>ht[i]; } for (int i=2 ;i<=n;i++){ if (ht[i]==-1 ){ int x=sa[i-1 ]+1 ,y=sa[i]+1 ; if (rk[x]>rk[y]) G[sa[i]].push_back (sa[i-1 ]); } else { int x=sa[i-1 ],y=sa[i]; for (int j=1 ;j<=ht[i];j++){ pre[root (x+j-1 )]=pre[root (y+j-1 )]; } if (x+ht[i]<=n) G[y+ht[i]].push_back (x+ht[i]); } } ans[sa[1 ]]='a' ; for (int i=2 ;i<=n;i++){ ans[sa[i]]=ans[sa[i-1 ]]; for (auto v:G[sa[i]]){ if (ans[v]+1 >ans[sa[i]]) ans[sa[i]]=ans[v]+1 ; } for (int j=1 ;j<n;j++){ if (root (sa[j])==root (sa[i])) ans[sa[j]]=ans[sa[i]]; } } for (int i=1 ;i<=n;i++) cout<<ans[i]; return 0 ; }
P5353
可以参考 STARSczy题解的思路 ,这里我就不再详细展开了(打字太累了 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <bits/stdc++.h> using namespace std;constexpr int MN=1e6 +15 ;int n,fa[MN],rk[MN],c[MN],sa[MN],x[MN],y[MN],tmp[MN];string s; vector<int > adj[MN]; namespace SAonTree{ void dfs (int u) rk[u]+=c[rk[u]]++; sort (adj[u].begin (),adj[u].end ()); for (int v:adj[u]) dfs (v); } void getsa (string s) int len=s.length (); memset (c,0 ,sizeof (c)); for (int i=1 ;i<=len;i++) c[s[i-1 ]+1 ]++; for (int i=1 ;i<=1000 ;i++) c[i]+=c[i-1 ]; for (int i=1 ;i<=len;i++) rk[i]=c[s[i-1 ]]+1 ; for (int w=0 ;w<=__lg(len);w++){ memset (c,0 ,sizeof (c)); memset (tmp,0 ,sizeof (tmp)); for (int i=1 ;i<=len;i++){ x[i]=rk[i]; y[i]=rk[fa[i]]; c[y[i]+1 ]++; } for (int i=1 ;i<=len;i++) c[i]+=c[i-1 ]; for (int i=1 ;i<=len;i++) tmp[++c[y[i]]]=i; memset (c,0 ,sizeof (c)); for (int i=1 ;i<=len;i++) rk[tmp[i]]+=c[x[tmp[i]]]++; for (int i=1 ;i<=len;i++) sa[rk[i]]=i; for (int i=1 ;i<=len;i++){ if (x[sa[i-1 ]]==x[sa[i]] && y[sa[i-1 ]]==y[sa[i]]) rk[sa[i]]=rk[sa[i-1 ]]; } for (int i=len;i>=1 ;i--) fa[i]=fa[fa[i]]; } memset (c,0 ,sizeof (c)); dfs (1 ); for (int i=1 ;i<=len;i++) sa[rk[i]]=i; } } int main () ios::sync_with_stdio (0 );cin.tie (0 ); cin>>n; for (int i=2 ;i<=n;i++){ cin>>fa[i]; adj[fa[i]].push_back (i); } cin>>s; SAonTree::getsa (s); for (int i=1 ;i<=n;i++) cout<<sa[i]<<" " ; return 0 ; }
例题:
P5346
假设我们求出来了n n n
操作 1:O ( 1 ) O(1) O ( 1 ) 操作 2:考虑主席树求第k k k O ( log n ) O(\log n) O ( log n ) 操作 3:按照 DFN 序更新即可。O ( log n ) O(\log n) O ( log n ) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 #include <bits/stdc++.h> using namespace std;constexpr int MN=2e6 +15 ;int n,q,fa[MN],a[MN],b[MN],tot;vector<int > adj[MN],s; struct Segment {#define ls t[p].lson #define rs t[p].rson struct Node { int lson,rson,val; }t[MN*20 +1145 ]; int tot,rt[MN]; int insert (int lst,int l,int r,int x) int p=++tot; t[p]=t[lst]; t[p].val+=1 ; if (l==r) return p; int mid=(l+r)>>1 ; if (mid>=x) ls=insert (t[lst].lson,l,mid,x); else rs=insert (t[lst].rson,mid+1 ,r,x); return p; } int query (int u,int v,int l,int r,int k) if (l==r) return l; int mid=(l+r)>>1 ; int rz=t[t[v].rson].val-t[t[u].rson].val; if (k<=rz) return query (t[u].rson,t[v].rson,mid+1 ,r,k); return query (t[u].lson,t[v].lson,l,mid,k-rz); } #undef ls #undef rs }sg0,sg1; namespace ly{ namespace IO { #ifndef LOCAL constexpr auto maxn=1 <<20 ; char in[maxn],out[maxn],*p1=in,*p2=in,*p3=out; #define getchar() (p1==p2&&(p2=(p1=in)+fread(in,1,maxn,stdin),p1==p2)?EOF:*p1++) #define flush() (fwrite(out,1,p3-out,stdout)) #define putchar(x) (p3==out+maxn&&(flush(),p3=out),*p3++=(x)) class Flush {public :~Flush (){flush ();}}_; #endif namespace usr { template <typename type> inline type read (type &x) { x=0 ;bool flag (0 ) char ch=getchar (); while (!isdigit (ch)) flag^=ch=='-' ,ch=getchar (); while (isdigit (ch)) x=(x<<1 )+(x<<3 )+(ch^48 ),ch=getchar (); return flag?x=-x:x; } template <typename type> inline void write (type x) { x<0 ?x=-x,putchar ('-' ):0 ; static short Stack[50 ],top (0 ); do Stack[++top]=x%10 ,x/=10 ;while (x); while (top) putchar (Stack[top--]|48 ); } inline char read (char &x) do x=getchar ();while (isspace (x));return x;} inline char write (const char &x) return putchar (x);} inline void read (char *x) static char ch;read (ch);do *(x++)=ch;while (!isspace (ch=getchar ())&&~ch);} template <typename type>inline void write (type *x) while (*x)putchar (*(x++));} inline void read (string &x) static char ch;read (ch),x.clear ();do x+=ch;while (!isspace (ch=getchar ())&&~ch);} inline void write (const string &x) for (int i=0 ,len=x.length ();i<len;++i)putchar (x[i]);} template <typename type,typename ...T>inline void read (type &x,T&...y) read (x),read (y...);} template <typename type,typename ...T> inline void write (const type &x,const T&...y) {write (x),putchar (' ' ),write (y...),sizeof ...(y)^1 ?0 :putchar ('\n' );} template <typename type> inline void put (const type &x,bool flag=1 ) {write (x),flag?putchar ('\n' ):putchar (' ' );} } #ifndef LOCAL #undef getchar #undef flush #undef putchar #endif }using namespace IO::usr; }using namespace ly::IO::usr; namespace SAonTree{ int rk[MN],c[MN],tmp[MN],x[MN],y[MN],sa[MN]; void dfs (int u) rk[u]+=c[rk[u]]++; sort (adj[u].begin (),adj[u].end ()); for (int v:adj[u]) dfs (v); } void getsa (vector<int > s) int len=s.size (); memset (c,0 ,sizeof (c)); for (int i=1 ;i<=len;i++) c[s[i-1 ]+1 ]++; for (int i=1 ;i<=5e5 ;i++) c[i]+=c[i-1 ]; for (int i=1 ;i<=len;i++) rk[i]=c[s[i-1 ]]+1 ; for (int w=0 ;w<=__lg(len);w++){ memset (c,0 ,sizeof (c)); memset (tmp,0 ,sizeof (tmp)); for (int i=1 ;i<=len;i++){ x[i]=rk[i]; y[i]=rk[fa[i]]; c[y[i]+1 ]++; } for (int i=1 ;i<=len;i++) c[i]+=c[i-1 ]; for (int i=1 ;i<=len;i++) tmp[++c[y[i]]]=i; memset (c,0 ,sizeof (c)); for (int i=1 ;i<=len;i++) rk[tmp[i]]+=c[x[tmp[i]]]++; for (int i=1 ;i<=len;i++) sa[rk[i]]=i; for (int i=1 ;i<=len;i++){ if (x[sa[i-1 ]]==x[sa[i]] && y[sa[i-1 ]]==y[sa[i]]) rk[sa[i]]=rk[sa[i-1 ]]; } for (int i=len;i>=1 ;i--) fa[i]=fa[fa[i]]; } memset (c,0 ,sizeof (c)); dfs (1 ); for (int i=1 ;i<=len;i++) sa[rk[i]]=i; for (int i=1 ;i<=n;i++){ a[i]=rk[i]; } } }using namespace SAonTree; namespace Tree{ int siz[MN],dfn[MN],dtot; void dfsTree (int u) dfn[u]=++dtot; siz[u]=1 ; sg1. rt[dfn[u]]=sg1. insert (sg1. rt[dfn[u]-1 ],1 ,n,a[u]); for (auto v:adj[u]){ sg0. rt[v]=sg0. insert (sg0. rt[u],1 ,n,a[v]); dfsTree (v); siz[u]+=siz[v]; } } }using namespace Tree; int main () read (n,q); for (int i=2 ;i<=n;i++){ read (fa[i]); adj[fa[i]].push_back (i); } for (int i=1 ;i<=n;i++){ read (a[i]); b[++tot]=a[i]; } sort (b+1 ,b+1 +tot); tot=unique (b+1 ,b+1 +tot)-b-1 ; for (int i=1 ;i<=n;i++){ a[i]=lower_bound (b+1 ,b+1 +tot,a[i])-b; s.push_back (a[i]); } getsa (s); sg0. rt[1 ]=sg0. insert (0 ,1 ,n,a[1 ]); dfsTree (1 ); while (q--){ int op,x,k; read (op,x); if (op==1 ){ put (n+1 -a[x]); }else if (op==2 ){ read (k); put (sa[sg0. query (0 ,sg0. rt[x],1 ,n,k)]); }else { read (k); put (sa[sg1. query (sg1. rt[dfn[x]-1 ],sg1. rt[dfn[x]+siz[x]-1 ],1 ,n,k)]); } } return 0 ; }
实际上,我们一些技巧基本都体现了我们开头所提到的增量法与势能分析,通过已求信息逐步推导新信息。一些技巧例如关键点思想或并查集块合并通过将全局问题转化为局部问题,动态问题转化为静态问题。
字符串后缀,是字符串的大杀器,在做题过程中,我们能够体会到后缀独特的性质,能够将我们必须暴力枚举的子串简单化,并且将它的对立面——前缀联系起来,后缀数组这一利器,能够解决大部分的问题,但是,有一些问题是后缀数组所不能解决的。这个时候,就要出动我们的 SAM 啦,敬请期待,字符串终极神器——后缀自动机 - 洛谷专栏 。
UPD on 2025.7.7:孩子们,我题全部都做完了,结果练 SAM 发现题单里的题都用后缀数组实现过一遍了,充分证明了 SA 可以替代大部分 SAM 。然而不是这样的。
完结撒花!
参考